




中国饮料柠檬史:十年沉浮,酸倒一地,成就一片!
"没有哪一家公司具有全面的资源和技术平台。品牌商要积极寻找适合自己的资源,并且串联起来为自己服务。企业学会运用第三方技术和数据资源会成为一种核心竞争力。"
在技术主导的今天,个性化营销不再是奢侈品。数据库技术被各行业使用,也走进了中小企业,成为推动收入和赢得市场份额的重要手段。研究表明相关的用户沟通可以创造持久的忠诚度,并推动收入增长10%至30%。
个性化营销的思维是把每个用户当作个人来进行沟通,期望因此能够改善用户体验,推动销售收入。个性营销是对某一类用户的营销。用户分类是一个相对的概念,可以是某一群用户,也可以具体到某一个人。
如何描述某一类用户的特征呢?在过去,用户属性和心理属性分类是最常见的描述方法。属性分类和心理分类数据来源于“手工”收集的问卷数据,只能在宏观的层面描述用户,不能满足更高程度的个性化营销的需求。大数据基于用户的行为,其丰富程度和实效性是以前不能想象的。受众分类变得越来越动态,越来越细,到了以个人为分类标准的“粉碎”化程度,定义用户的方式从“分类”走向“粉碎”。“用户标签”,“千人千面”,“动态创意”等成为网红词汇。个性化营销有必要需要重新去理解,跟上时代的步伐。
从笔者服务客户的经验看来,品牌商应用个性化营销的效果是几家欢喜几家愁。虽然个性化带来了好处,但如果营销人员弄错了,也需要付出代价,而且失败的成本是相当高。效果不好的重要原因是企业还在沿用过去的思维方式去理解个性化营销,这就容易闯入“营销误区”。本文试图总结个性化营销常见的误区。
误区1:选人OR选媒介?
大众营销时代,受众是根据属性分类等粗犷的方法界定的,个性化的首要任务在沟通层面。但在大数据时代,确定谁是受众是营销的首要问题。
市场上所有的人都可以是受众,受众之间差别是购买产品的可能性。有的受众不看广告也会买你的产品,有的看再多次广告也不会买,所以给这两种用户做销售广告都是浪费。

假设市场上一共有200个潜在用户,而且你能算出其中一组100个用户购买产品的可能性为70%,另一组的100个用户可能性为30%。营销预算只允许你展示100次广告,你会怎么办呢?自然的做法就是对可能性高的100个人去分别展示一次广告,完全放弃另外一组用户。所以营销的重要的问题是如何挑选出那100个可能性更大的用户。
个性化营销是针对最可能对你广告有回应的一群用户。至于是否需要对这群人“千人千面“地沟通,是个次要的问题。即使是广告内容单一的传统广告也一直在说要针对不同的人群做广告,可以看出选人的重要性。但传统时代选用户要通过媒介。品牌商先要看媒介吸引什么样的用户,然后去购买媒介。如果是户外或楼宇广告,就要看周边人流特征。数字媒体中按内容分类的垂直媒体,比如汽车专栏,具有一定的人群精准性。但按照媒介特点去选受众毕竟是间接的,所以精准性很有限。
收益于大数据工具,如今广告主可以先选用户,再选传播媒介,实现按“人”投放广告的目的。做法是当一个人访问媒体的时候,品牌商会用数据判断这个用户是否达到自己选择的标准。如果不是,就不投广告。有了这样的目标人群后,品牌商就有更大的选择媒介渠道的自由。
当今盛行的语音识别、人脸识别、文本识别技术,和机器深度学习,把用户识别能力推上另一个台阶。此外,品牌商还能得益于数据整合能力,运用第3方数据资源来提升选择用户的能力。某酒店品牌要提升网上的订房率。过去是依靠媒体投放和转化数据去判断人群,数据标签上是有限的。如今这个客户可以用其他数据源,包含线下数据、语音文本数据等等去“撞库”,就能让用户的画像更清晰,从而提升选取用户的质量。
误区2:用户定义与产品特点没有关联
定义用户就是给用户打上“标签”,比如男性女性等。也许是受传统营销的影响,品牌商在给用户打标签的时候,没有去考虑产品的特征。例如,传统的RFM用户定义法,就是用户上一次购买的时间(Recency)、购买频率(Frequency)和过去购买商品的价值(Monetary value)去给用户打标签,然后用这三种数据把用户分层,每一层的用户推荐不同的产品。“VIP”用户通常就是三种数据价值都比较高,给他们推荐和沟通的方式区别于别的用户。RFM没有用到大数据,对用户价值的描述虽然比属性分类更实用,仍存在不少局限。RFM认为上次购买时间越近的用户,再购买的可能性更高。这其实不一定。当一个用户刚买了一件衣服,她再买一样的衣服可能性反而降低了。所以,如果你能看出用户与产品购买的关系,就能提升销售转化。
要靠技术算出用户与产品的关系,有几个关键。一是要有人群库,二是要建立产品或品牌的知识库。建立两个库之间的联系,依靠“模型”。提升模型的准确度的过程叫做“模型训练”。当一个用户搜索一个汽车品牌名字时,你就要迅速预测他是要找车系、配件还是汽车价格。如果输入的是一个具体车型,你就要预测他要找外观图片还是视频,是试驾还是上市时间等等,并且把这些需求进行排序。产品库包含所有产品的特征描述。拿汽车来讲,它可以有品牌、车系、车型、价格、动力、内饰外观等。最后,建立产品库的目的是为了实现与用户需求的匹配。匹配可以是双向的,可以用户匹配沟通信息,也可以按信息去匹配用户。这里举一个2B行业的实例来描述匹配模型的建立。某厂商产品是多种厨房用调料,要卖给全国各个餐馆的厨师。数据库中记录了3个不同餐馆的厨师购买4种产品的行为。厨师a买过产品2和3,厨师3买过所有产品,这个历史关系由下面示意图中红色箭头表示。
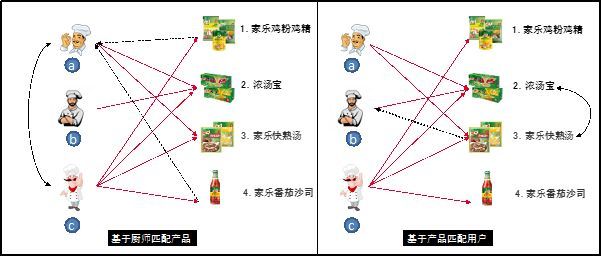
厨师a和c有共同属性(左图双向箭头所示),厨师a却没有购买过产品1和4,推荐模型就建议向厨师a推荐产品1和4(左图黑色虚线箭头表示推荐关系),这个过程就是基于用户去匹配产品。基于任何一个产品,我们看应该推荐给哪个用户。产品2是每个厨师都买了的。既然厨师b只用过产品2,产品3和产品2都是汤调料(右图双向箭头所示),可以给给厨师b推荐产品3(右图黑色虚线箭头)。这就是算法和机器学习中基于用户的协同过滤法(Collaborative Filtering)。哪种匹配方式效果更好呢,这需要用销售结果去比较和优化。还有其他建立推荐模型分方法,比如基于内容的推荐模型(Content based filtering),有兴趣的读者可以去研究。
误区3,把品牌营销的方式应用到销售上
品牌宣传的用户标签一般采用属性标签,比销售用的标签更粗犷。品牌传播用户的分类和销售传播的分类会很不一样。在用户属性层面,你会发觉宝马和奔驰车的用户都长得一样,对卖车缺乏指导意义。但如何用更好的方式去区分他们呢?这就需要更多、更细的行为标签。
从事数字运营的人员都体会数据实时对优化的重要性,所以这些用户标签要有很高的时效性。如果一个用户去过奔驰的官网,从概率上讲,他买奔驰的可能性也许大于买宝马,可以考虑投放奔驰广告。如果他最近还去了奔驰车展,那简直就成为重点沟通对象了。但如果这个用户刚刚购买了一辆奔驰车,你还会针对他做卖车的广告吗?
对于数据整合,几个流量巨头具有先天的优势,阿里的BrandDatabank,京东九数平台,相信美团、大众点评等推荐和销售都有不错的整合数据,这是因为他们的业务自然拥有用户线上和线下数据。有的还拥有用户媒体数据,就更能帮助营销。品牌商自己的数据资源是有限的,就需要联合行业上下游的伙伴一起来实现数据整合,大的媒体,比如新浪微博、微信等等,都有用户标签。有些用户标签是开放的,广告主可以用。除此以外,市场上还有不少包括笔者公司在内的,具有自然语言和图像采集能力和机器学习能力的资源。没有哪一家公司具有全面的资源和技术平台。品牌商要积极寻找适合自己的资源,并且串联起来为自己服务。企业学会运用第三方技术和数据资源会成为一种核心竞争力。
误区4,过分依赖第三方数据,在营销中采用别人的数据库
第3方数据有用,但不能完全依赖。天猫、京东、微博等大型平台都有用户标签供品牌广告主使用,用户被“城市白领”,“旅行人群”等之类的名称做好了标记,方便广告主运营使用。你用了就会发觉,第3方数据标签的效果时好时坏,并不统一。更大的问题是,你还不知道影响效果好坏的原因。况且标签是通用的,你的竞争对手也在用同样的标签,所以你很难跑赢“大盘”。大电商平台的数据标签不是为某一个品牌商专门设置的,而是为了服务自己的商业目的,比如卖掉更多流量。所以说,当你的用户是被别人定义的时候,效果很快就会出现瓶颈。
大的数据平台数据标签并不能满足品牌商个性化的需要。品牌商,包括他们的营销代理机构,希望得到更底层的用户“基础”数据,他们能够用这些基础数据去形成自己的标签。这样能够进一步解放数据资源的价值。当然,平台商应该收取相关的费用。媒体费用和数据费用有时可以分开,如果仍然是媒介收费而数据免费,就会象医院看病免费而靠卖药赚钱一样,第3方数据就不能按照广告主需求多元化、个性化。

误区5:用户的定义与营销目的没有关联
在化妆品品牌传播活动当中,聚焦女性用户没有错。但在销售活动中只瞄准女性用户就有问题了。我本人就常常为妻子购买化妆品。遗憾的是,我几乎没有收到过女性用产品的个性信息。营销具有很强的目的性,是提升知名度还是偏好度?是要拉新还是提升销售转化率?公司需要根据营销目的去定义受众。
笔者举一个自己公司的案例来试图说明如何避免营销误区。客户是一个服装行业的品牌。我们运用用户的历史购买数据建模,去预判购买服装的可能性。做法是把服装产品知识库标签化,然后与用户数据建立联系。服装的款式多达数千,加上用户数量也有几百万,数据量庞大,需要借助机器学习的手段来“训练”模型。我们要求客户明确营销目标是要提升产品的销售转化,(如果是要提升用户参与度等就不一样了,避免误区5)。
我们的方案是把目标聚焦在选择用户身上,而不追求沟通中要“千人千面“的个性化(避免误区1)。针对每一款服装,挑选出购买意愿最强的用户去做传播。当然“购买意愿最强”的人群数量界定,是要根据营销预算来计算的,这可以是购买可能性排在前10%的用户,也可以是排在前50%的用户。如果只推荐前10%的用户,转化率就高,但用户数量会少。如果你给所有用户(100%的用户)都推荐,你就获得一个市场平均值,这就跟大众广告没什么两样了。如何挑选用户呢?我们运用用户购买的历史销售数据去观察他们购买产品的特征(避免误区2),这些特征会是由产品图片、文字描述(休闲裤、套头、圆领等)、品牌销售内容文本等建立的。企业会销售新产品,或把产品交叉销售给不同的用户。结果是机器会给出每种用户一个购买意愿的评分。品牌商只需要决定推荐用户的比例,就能从数据库中提取相应的人群包了,无论是用在线上还是线下营销渠道。
值得一提的是,我们并不把用户戴上一个“小资白领”之类的帽子。而只关心对于某一款服装,这个用户购买意愿有多高。既然营销目标是提升产品的销售转化,机器会按照预算给出最可能转化的人群ID,营销时品牌就只针对这些用户进行沟通。所以模型链接了销售目标、用户和产品三种关系,形成一个完全定制的标签体系。模型开始建立时对于买还是没买判断的准确率可能不够高,但通过增加样本就能不断学习和提升准确值。
人工智能需要人和机器协同工作。人做的事情是设定目标和建立规则,比如确定标签的制定原则。人在数据训练过程中还要做一定干预,比如调整某个标签的权重,或者淘汰一些不适合的样本等等,是创造性质的;机器是提升规模和速度,是重复性质。一旦模型准确度达到要求,个性化营销需要的用户数据分析和匹配就都是机器的事情了。使用推荐系统后,有效商品浏览量得到提升,无效浏览量下降。虽然推荐的用户只占数据库全部用户的30%,他们的购买量占到实际购买用户中的67.3%,取得了比较理想的转化效果(见下图)
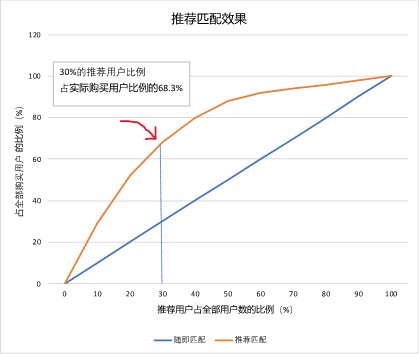
在过去,个性化营销由品牌商自己的市场部门就可以操作了。今天的个性化营销不但需要多方数据资源,而且需要与懂得数据商业应用的数据科学家或分析师一起协作。个性营销的实质是选取20%的用户去贡献80%的销售转化,这是依靠运用数据模型和机器学习建立品牌和用户的之间的个性关系。个性化营销的“二八原则”没有变,改变的是操作的方式。
作者:北京爱茵智能科技创始人兼CEO
更多干货、市场分析、重磅案例、实战课程欢迎订阅 [农业行业观察]公众号:nyguancha

相关文章
文章:292 篇
浏览:78427 次

深度研究!数字农业的发展趋势与推进路径..

「2026中国-安哥拉渔业和水产养殖论坛」释放商机..

【乡村振兴模式】六大主流乡村振兴实战模式..

中农金旺与清涧县签约合作协议,为清涧农业注入..

证书推荐!农业经理人技能证书,5月25日截止报名..

品牌农业的全产业链,到底有多长?..

【知识科普】智慧农业十大关键技术介绍..
印度农业结构升级:全球钾肥需求新引擎..

生态农业为何这么火?生态农业具有哪几大大优势..

多地都在申报!优势特色产业集群建设项目怎么申..

【智慧农业】机器人进大棚:设施农业自动化的技..

【生态农业】什么是生态农业,发展历程、背景、..

案例分析!数字赋能杭州建德草莓产业的实践与启..

【农业新模式】鱼菜共生的几种主要模式和主流技..

【政策解读】首次!生物基材料,写进“十五五”..

【智能农业】神农大模型:向新提质 强农报国..

2026年生物育种产业深度观察:在“十五五”前夕..

【世界农业案例】德国草莓农场的规划:欧洲经营..

【食品行业】未来已来!功能性食品创新之道(附P..

【农村电商】如何打通农村电商“最后一公里”?..

如何打造更赚钱的“无人农场”?

【预制菜】重磅分析!我国预制菜出海的趋势与特..

植物工厂掘金战:五大商业模式破解90%亏损魔咒!..

50万架农业无人机如何重塑全球农业?揭秘未来十..

【预制菜】2025预制菜趋势预测:聚焦大单品,迈..

70%利润归农户!“公司+合作社+农户”模式正在助..

出海,中国农业的下一站!

政策青睐!数字乡村如何从“盆景”变“风景”(..

【考证推荐】农业经理人技能证(第19期)7月4月..

【创业案例】逆天啊!蔬菜种成打卡项目,1斤卖价..













